
Fake News Detection
Introduction
The Fake News Challenge (FNC) is a competition to explore how machine learning can contribute to the detection of fake news. The first stage of the challenge is to accomplish something called stance detection. Given a short headline and an article, we need to categorize the relationship between the article and headline into 4 categories: Disagree, Agree, Unrelated, and Discusses.
The organizers of the FNC provided a database, which can be found here.
We need a method for capturing the meaning of the article and the headline if we want to be able to categorize their relationship. One architecture that can vectorize the meaning of a block of text is the encoder-decoder neural network. We are specifically interested in the encoder part, which is responsible for capturing the meaning of a block of text for the decoder section to work with. The encoder section is implemented as a stack of LSTM units, with each unit accepting a new word from the input text and taking input from the previous unit. The hidden state of the last LSTM unit can be intuitively thought of as a vector that captures the meaning of the entire input.
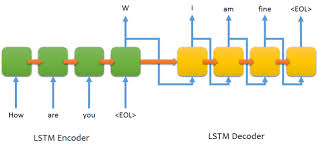
In addition, we’ll need to find a way to vectorize our data. Fortunately, Google has created the Word2Vec neural network which does the job for us. Google also made a pre-trained network that contains 3 million words represented by 300-dimensional vectors. We can use the Gensim Python package to load and use this model. A guide for doing so can be found here.
Architecture
We’ll use 2 encoders in our architecture - one to capture meaning from the article, and one to capture meaning from the headline. The hidden state from both encoders are passed to two fully connected feedforward layers, then to the final softmax layer. In addition, the initial state of the headline encoder is set to be the hidden state of the last LSTM unit in the article encoder.
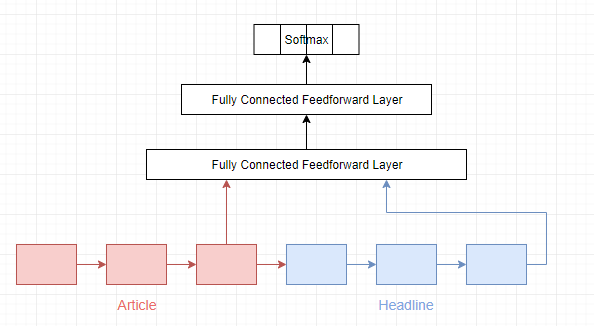
Results
We trained the network for 135 epochs and got the following confusion matrix as a result. The columns represent the output from our model, and the rows represent the correct answer.
| agree | disagree | discuss | unrelated | |
|---|---|---|---|---|
| agree | 128 | 0 | 142 | 582 |
| disagree | 21 | 0 | 28 | 209 |
| discuss | 152 | 16 | 433 | 1759 |
| unrelated | 672 | 22 | 1413 | 6469 |
Score: 2268.0 out of 5614.0 (40.399002493765586%)
Not too bad! Although the dataset is heavily skewed toward the Unrelated category, we see that our network was still occasionally able to recognize the other 3 categories.
Possible Improvements
Because the dataset is unbalanced (there are too many data points in the Unrelated category), our network will be biased toward the Unrelated category. This can be somewhat remedied by using a penalized model. This type of model increases the error incurred when the network makes a mistake on classifying the underrepresented categories, and helps bias the model toward these categories.